
Why should you read this? If you are a web developer who wants to achieve faster time to market for new products and features, cut (almost eliminate) time to provision and manage infrastructure, minimize downtime and security risks, along with costs - this is the place for you. This article will teach you how easy it is to make a simple serverless app that is scalable and highly available.
We will cover this topic using Serverless Framework for managing AWS services with a small amount of coding since you already know how to do that. Previous AWS experience or knowledge isn’t required for understanding this article.
What is Serverless?
Serverless characteristics:
 Serverless is generally defined as an execution model in cloud computing where a cloud provider allocates and bills machine resources on demand. This means that you do not care about the underlying infrastructure, have flexible scaling and high availability while focusing on solving the problem at hand. You only care about the what, not the how.
Serverless is generally defined as an execution model in cloud computing where a cloud provider allocates and bills machine resources on demand. This means that you do not care about the underlying infrastructure, have flexible scaling and high availability while focusing on solving the problem at hand. You only care about the what, not the how.
The Serverless Framework allows you to manage resources with ease and without any previous knowledge of the cloud platform (in our case, AWS).
How is web development different when using Serverless?
When we develop an API, we usually choose:
- Programming language
- Web framework
- Database
When developing an API as a Serverless we choose:
- Programming language
- Cloud platform
- Database
The list of services is usually more comprehensive in real-world scenarios (Message broker, email service, etc.), but for the sake of simplicity, we will stick with the aforementioned services. As you can see, cloud platforms can be considered a development framework, where you use cloud services as building blocks of your application. While having a vendor-locking as a potential downside, you substantially benefit from the well-connected ecosystem. You are not “reinventing the wheel”, but focusing on your business case.
Lambda function that handles REST request
AWS Lambda is what it ultimately promises - A LAMBDA, a.k.a., a function.
Prerequisites
- Install Serverless framework cli - we will use its alias: sls
- Configure AWS credentials
- Install Node.js 12.x or later
Lambda in a nutshell
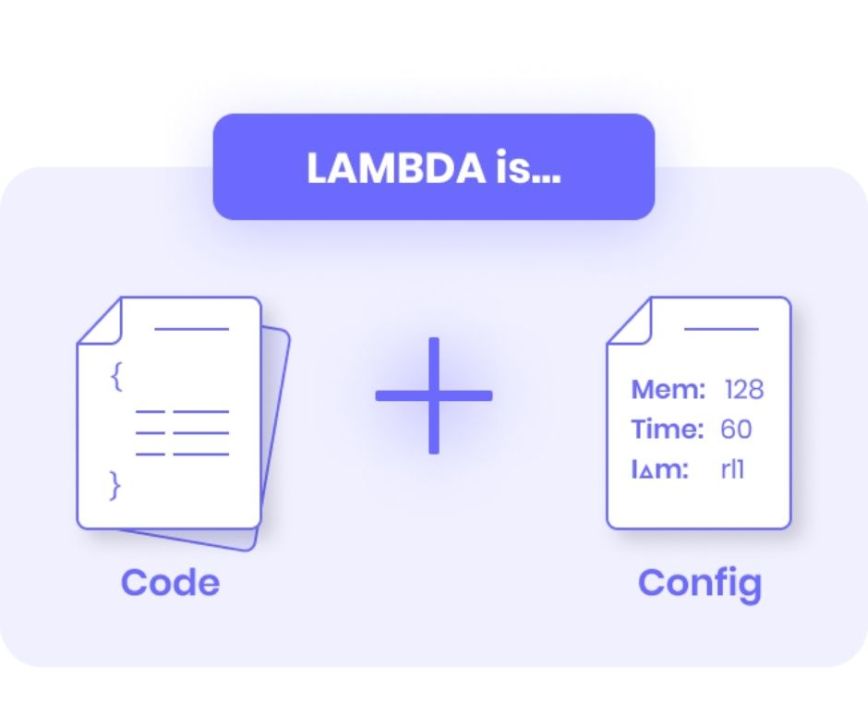
Let's write some “code” You can find an example code on GitHub to follow through, or write the code along the way.
Create folder structure

Update file ‘handler.js’ with the following code
module.exports.hello = async () => {
return {
statusCode: 200,
body: 'Hello there!'
};
};
Code part - DONE.
Update file ‘serverless.yaml’ with the following configuration
service: myapp frameworkVersion: '2' provider: name: aws runtime: nodejs12.x functions: hello: handler: handler.hello
Configuration part - DONE.
- service: the name of the service we are writing (it can contain multiple Lambda functions).
- provider: the provider-specific configuration
- functions: all the functions
In this example, the “hello” function handler is in “handler.hello” which means a file named “handler.js” and “hello” being the name of the exported property.
We can now execute sls deploy and have our first Lambda function created.
Right now, our Serverless environment looks like this:
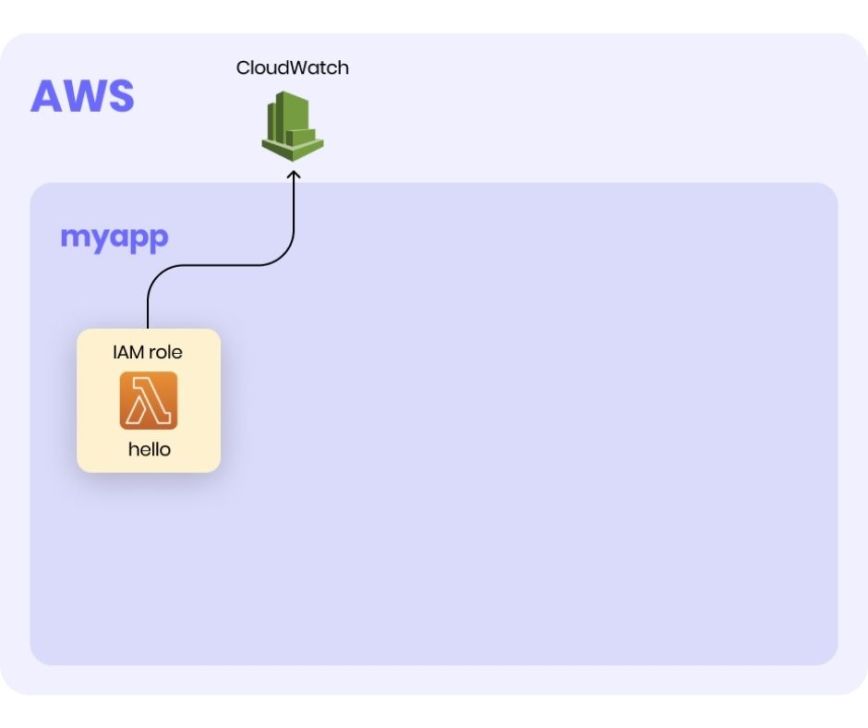
At this point, we still haven't put the Lambda function we created into use.
What Serverless framework did in the background:
- Create myapp Stack - (Stack = collection of AWS resources)
- Create IAM Role - Lambda runs under a specific execution role and communicates with the rest of the AWS services as an assigned execution role.
- Create hello Lambda; By default, Lambda will create an execution IAM role with permissions to upload logs to Amazon CloudWatch Logs.
How can we use our Lambda function?
Since we want to create an HTTP endpoint, we need to subscribe our hello Lambda function to an HTTP event.
Create an HTTP trigger for our Lambda function functions:
functions: hello: handler: handler.hello events: - http: path: /hello method: get
Again: sls deploy
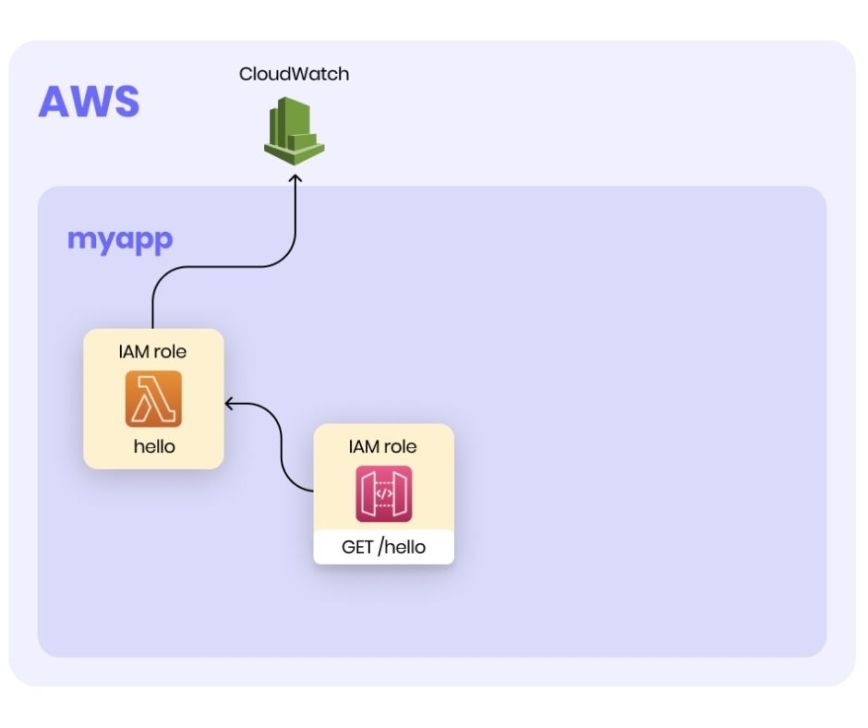
- Create an API Gateway resource
- Expose HTTP API endpoint and invoke hello Lambda function on GET /hello request.
- Adds permission to invoke our Lambda function
Create a database and endpoints to manipulate the data
Every web application works with some data. We will create the following endpoints:
- POST /tasks - create a new task
- GET /tasks/:id - get created tasks
When creating a database, we need to consider what kind of database we need. Next, since the Lambda function will consume the database, we should consider the risk of losing the Serverless characteristics due to the database being a bottleneck.
Our example does not require a relational database, so we choose DynamoDB.
Update configuration to create DynamoDB. Details of the DynamoDB configuration are a separate topic, and we will not cover it in this post. In short, the table will have an “id” that is a string as the primary key. You can find details about workload (provisioned throughput) here.
resources: Resources: TasksTable: Type: AWS::DynamoDB::Table Properties: TableName: tasksTable AttributeDefinitions: - AttributeName: id AttributeType: S KeySchema: - AttributeName: id KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1
Lambda function (its underlying role) must have appropriate permissions for the DynamoDB table (no username/password/connection string in the configuration, just specific permissions) in order to use the DynamoDB table. When enabling permissions, try to be as conservative as possible. We do not want a role to have particular permission if it does not need it.
We will now add permissions for database access:
provider: ... iamRoleStatements: - Effect: Allow Action: - dynamodb:GetItem - dynamodb:PutItem Resource: !GetAtt TasksTable.Arn
!GetAtt logicalNameOfResource.attributeName is used to pull the “arn” (resource identifier) of the DynamoDB table we created.
Now we will create two lambdas to create and fetch records from the database.
module.exports.createTask = async (event) => {
const id = new Date().getTime().toString();
var params = {
TableName: "tasksTable",
Item: {
id,
data: JSON.parse(event.body),
},
};
await documentClient.put(params).promise();
return {
statusCode: 201,
headers: {
Location: `/tasks/${id}`,
},
};
};
module.exports.getTaskById = async (event) => {
const id = event.pathParameters.id;
var params = {
TableName: "tasksTable",
Key: {
id,
},
};
const item = await documentClient.get(params).promise();
return {
statusCode: 200,
body: JSON.stringify(item.Item.data),
};
};
We also need a configuration to make this code a lambda function.
functions:
...
createTask:
handler: handler.createTask
events:
- http:
path: /tasks
method: post
getTaskById:
handler: handler.getTaskById
events:
- http:
path: /tasks/{id}
method: get
Aaaaand we sls deploy once again.
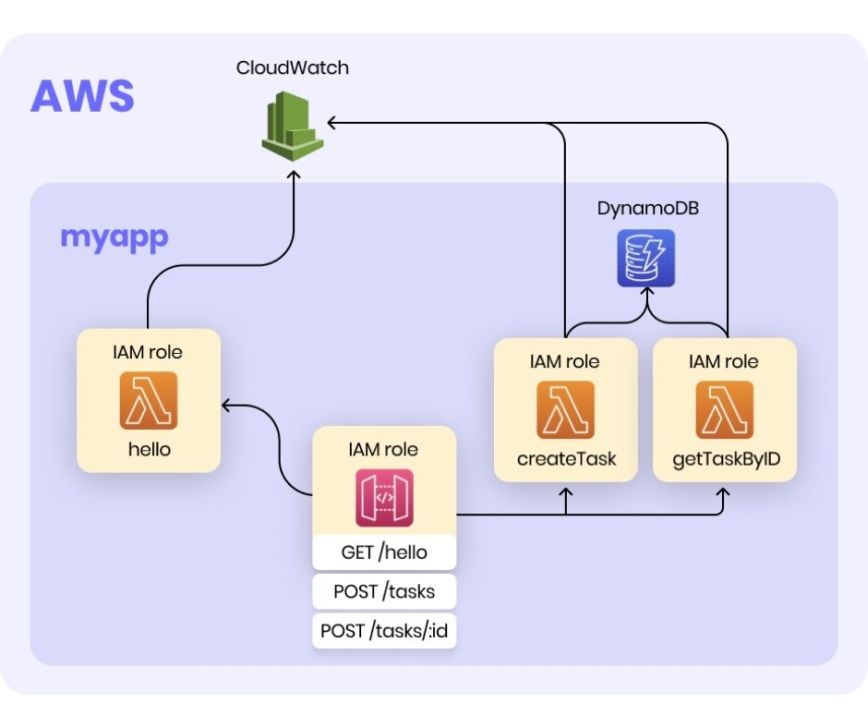 Now sls created:
Now sls created:
- DynamoDB table
- createTask and getTaskById Lambdas
- Permissions to write logs into the CloudWatch - implicit
- Permissions to Get/Put items in DynamoDB table - explicit
- Updated API Gateway with new handlers
- Permissions for API Gateway to invoke new Lambdas
We can start creating records in the database and pulling those records using record ID.
And that's it! With zero effort in designing the infrastructure (VMs, networks, load balancers, etc.) we now have a scalable and highly available application that is billed per usage - this is the true power of serverless.
About the author
Robert Sebescen is a Solutions Architect working at our engineering hub in Novi Sad.
Robert’s strongest points are problem-solving skills and figuring out how stuff works. Most experience and most comfortable working with .NET Core framework on the backend and React on the front-end. Practices Scrum and considers all of its components equally important. As a solution architect, he did estimations for a few integration projects covering: scoping the functional and non-functional requirements, investigating the feasibility of the integration by analyzing platforms (and their APIs) that participate in the integration, defining a solution, and estimating required effort and workforce.
For more information about symphony visit their profile!